uname -a # 查看正在使用的内核,e.g. linux-image-4.15.0-88-generic sudo apt-mark hold linux-image-4.15.0-88-generic
若成功,可以看到显卡信息。
插曲
在安装dkms时出现了两个小问题:
1、当前源中找不到相应的安装包
1 2 3 4 5 6 7 8 9 10 11 12 13 14
1)使用 sudo vim /etc/apt/sources.list 修改镜像源 2)然后执行 sudo apt-get update 更新
## 阿里源 deb http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse
2、该死的samba服务报错信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
dpkg: error processing package samba (--configure): dependency problems - leaving unconfigured Errors were encountered while processing: samba-common samba-common-bin samba E: Sub-process /usr/bin/dpkg returned an error code (1)
# Download the helper library from https://www.twilio.com/docs/python/install from twilio.rest import Client
# Your Account Sid and Auth Token from twilio.com/console # DANGER! This is insecure. See http://twil.io/secure account_sid = 'your_acco_sid' auth_token = 'your_auth_token' client = Client(account_sid, auth_token)
message = client.messages \ .create( body="Join Earth's mightiest heroes. Like Kevin Bacon.", from_='+150XXXXXXXXX', to='+86XXXXXXXXXXX' )
import pandas as pd import numpy as np import os import matplotlib.pyplot as plt
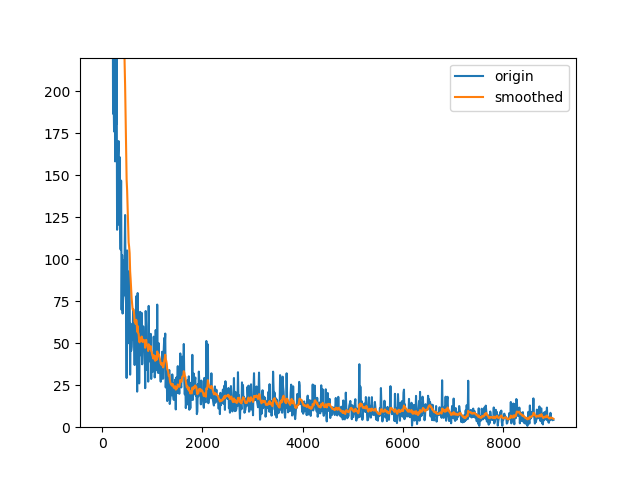
defsmooth(csv_path, weight=0.85): data = pd.read_csv(filepath_or_buffer=csv_path, header=0, names=['Step','Value'], dtype={'Step':np.int, 'Value':np.float}) scalar = data['Value'].values last = scalar[0] smoothed = [] for point in scalar: smoothed_val = last * weight + (1 - weight) * point smoothed.append(smoothed_val) last = smoothed_val
save = pd.DataFrame({'Step':data['Step'].values, 'Value':smoothed}) save.to_csv('smooth_' + csv_path)
defsmooth_and_plot(csv_path, weight=0.85): data = pd.read_csv(filepath_or_buffer=csv_path, header=0, names=['Step','Value'], dtype={'Step':np.int, 'Value':np.float}) scalar = data['Value'].values last = scalar[0] print(type(scalar)) smoothed = [] for point in scalar: smoothed_val = last * weight + (1 - weight) * point smoothed.append(smoothed_val) last = smoothed_val
# save = pd.DataFrame({'Step':data['Step'].values, 'Value':smoothed}) # save.to_csv('smooth_' + csv_path)
defsetup_seed(seed=202003): random.seed(seed) np.random.seed(seed) # if you are suing GPU torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) # if you are using multi-GPU # for cudnn torch.backends.cudnn.enabled = False torch.backends.cudnn.benchmark = False torch.backends.cudnn.deterministic = True # for hash os.environ['PYTHONHASHSEED'] = str(seed)