最近在使用YOLOv3模型来训练KITTI数据集,遇到一个不可避免的问题——可复现性。由于所参考的代码(PyTorch_YLOv3)没有做相关的设置,因此也费了些时间去了解和实践。
官方的指导文件见:https://pytorch.org/docs/master/notes/randomness.html ,具体而言,需要考虑以下几个方面:
随机种子的设定
Pytorch的种子设置(CPU&GPU)
1
2torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPUcuDNN的优化设置
1
2
3torch.backends.cudnn.enabled = False
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = TruecuDNN使用非确定性算法,能够自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题,可以使用
torch.backends.cudnn.enabled = False来进行禁用。当然,禁用后会影响一定的效率。Numpy的种子设置
1
np.random.seed(seed)
对于目标检测等任务来说,经常需要进行数据增强,如随机翻转、多尺度训练等,可以通过设置Numpy的种子来去除非确定性。此外,Pytorch的底层实现中某些模块也调用了Numpy的随机性操作,所以不管是否进行了数据增强操作,都需要设置Numpy的种子。
DataLoader的多线程设置
当DataLoader采用多线程操作时(num_workers > 1),也需要进行随机种子的设置。
1
2
3
4def _init_fn():
np.random.seed(0)
train_loader = DataLoader(data_sets, batch_size=8, shuffle=True,
num_workers=8, worker_init_fn=_init_fn)random模块设置
1
random.seed(seed)
Pytorch底层实现代码对于非确定性的引入
在进行了上述种子设定后,代码基本上具备了可重复性,然而目前Pytorch的某些底层实现仍然存在着不确定性,暂时无法得到解决。比如,Pytorch的上采样操作在反向求导时会存在随机性;API所述,PyTorch使用的CUDA实现中,有一部分是原子操作,尤其是
atomicAdd,使用这个操作就代表数据不能够并行处理,需要串行处理,使用到atomicAdd之后就会按照不确定的并行加法顺序执行,从而引入了不确定因素。PyTorch中使用到的atomicAdd的方法:前向传播时:
- torch.Tensor.index_add_()_
- torch.Tensor.scatter_add()
- torch.bincount()
反向传播时:
- torch.nn.functional.embedding_bag()
- torch.nn.functional.ctc_loss()
- 其他pooling,padding, sampling操作
这次在进行YOLOv3(Pytorch版)的训练时,采用的种子设定脚本为:
1 | def setup_seed(seed=202003): |
最后一行主要是为了禁止hash随机化,使得实验可复现。但是因为YOLOv3中含有上采样层,所以在进行实验时发现,在训练前期结果可以保持一致性,但随着epoch的增大,也会产生一定的不确定性,取两组训练过程的Loss可视化如下:
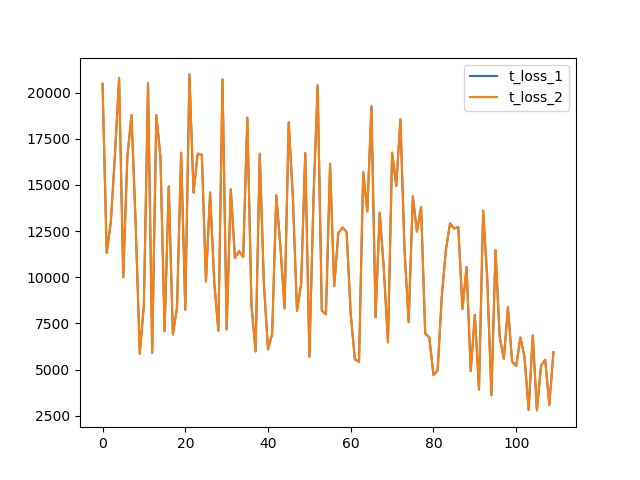
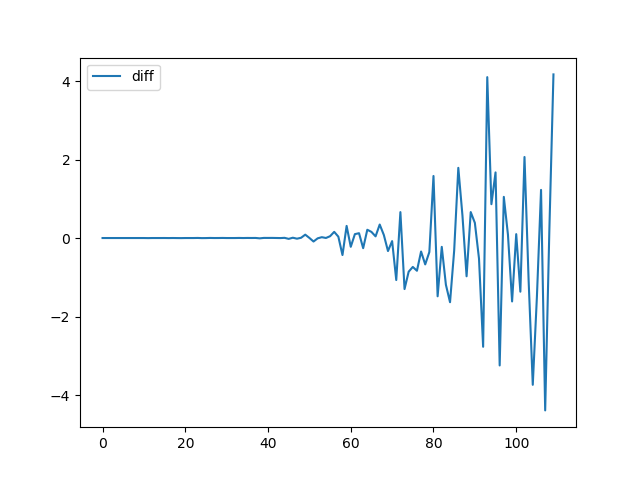
Ref:
PyTorch中模型的可复现性 - 知乎
https://zhuanlan.zhihu.com/p/109166845
Deterministic Pytorch: pytorch如何保证可重复性 - 知乎
https://zhuanlan.zhihu.com/p/81039955
Set All Seed But Result Is Non Deterministic - PyTorch Forums
https://discuss.pytorch.org/t/set-all-seed-but-result-is-non-deterministic/27494